Overview of Data Management
In JAMScript, nodes are independent (i.e., have separate address spaces). All data processing that happens in a node are local to that node. From what we have seen so far, only way of exchanging data between nodes is to use parameter passing (i.e., message passing implemented via remote task invocations).
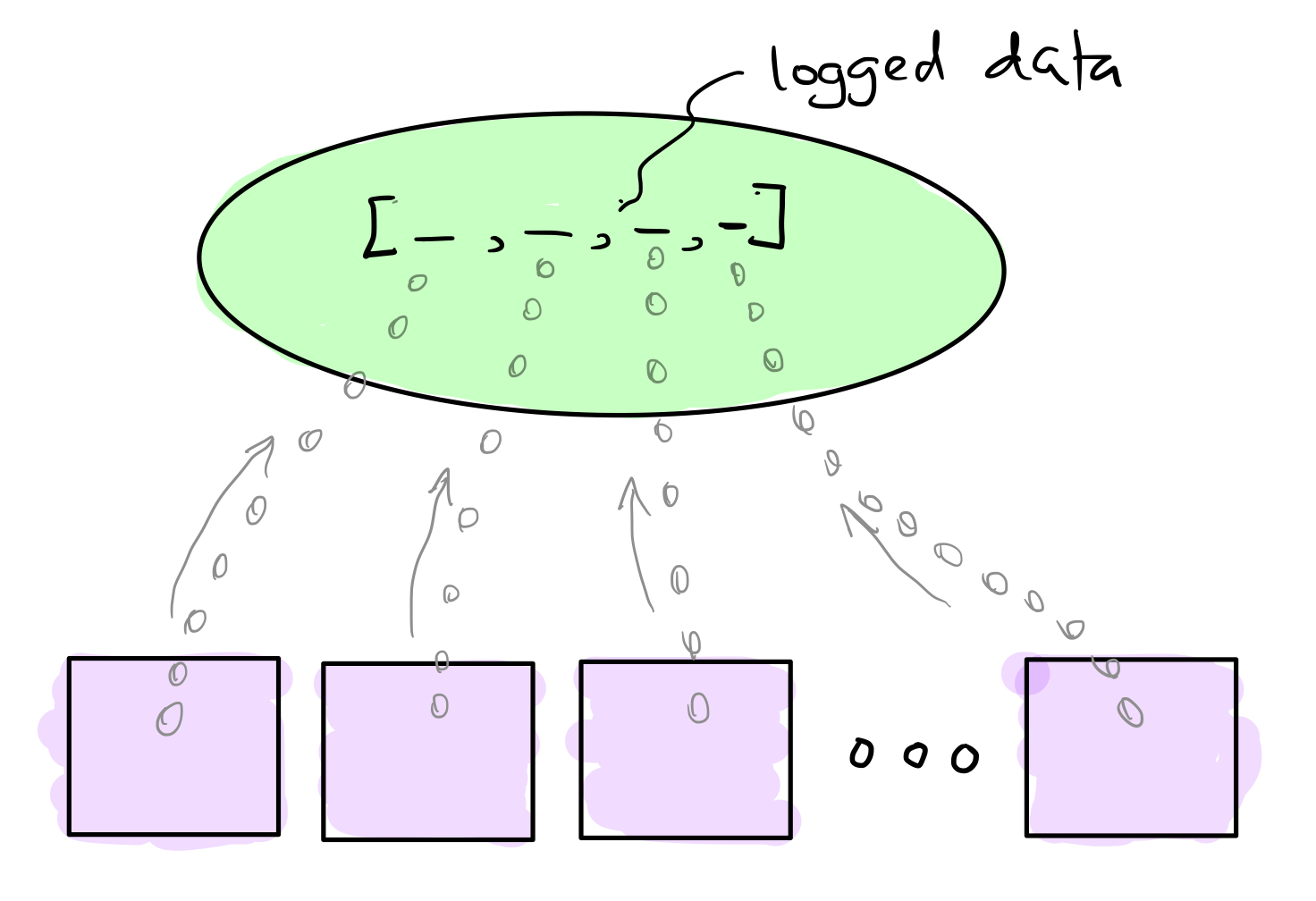
In edge-oriented IoT, devices can push data at high rate towards the edge for processing. The edge computers (i.e., fogs) process the data before passing it to the cloud. We need another mechanism besides the parameter passing to exchange such high rate data. JAMScript introduces logger as the key mechanism for pushing data from the devices to the fogs and from the fogs to the cloud. The diagram below illustrates a simple scenario that could happen within a single device. We have a controller and many workers in this scenario. The workers produce the data and push it towards the controller. The logger structure organizes the data into streams. There is one stream corresponding to each worker. We can slice the stream at any given instance to get an array of data for analysis.
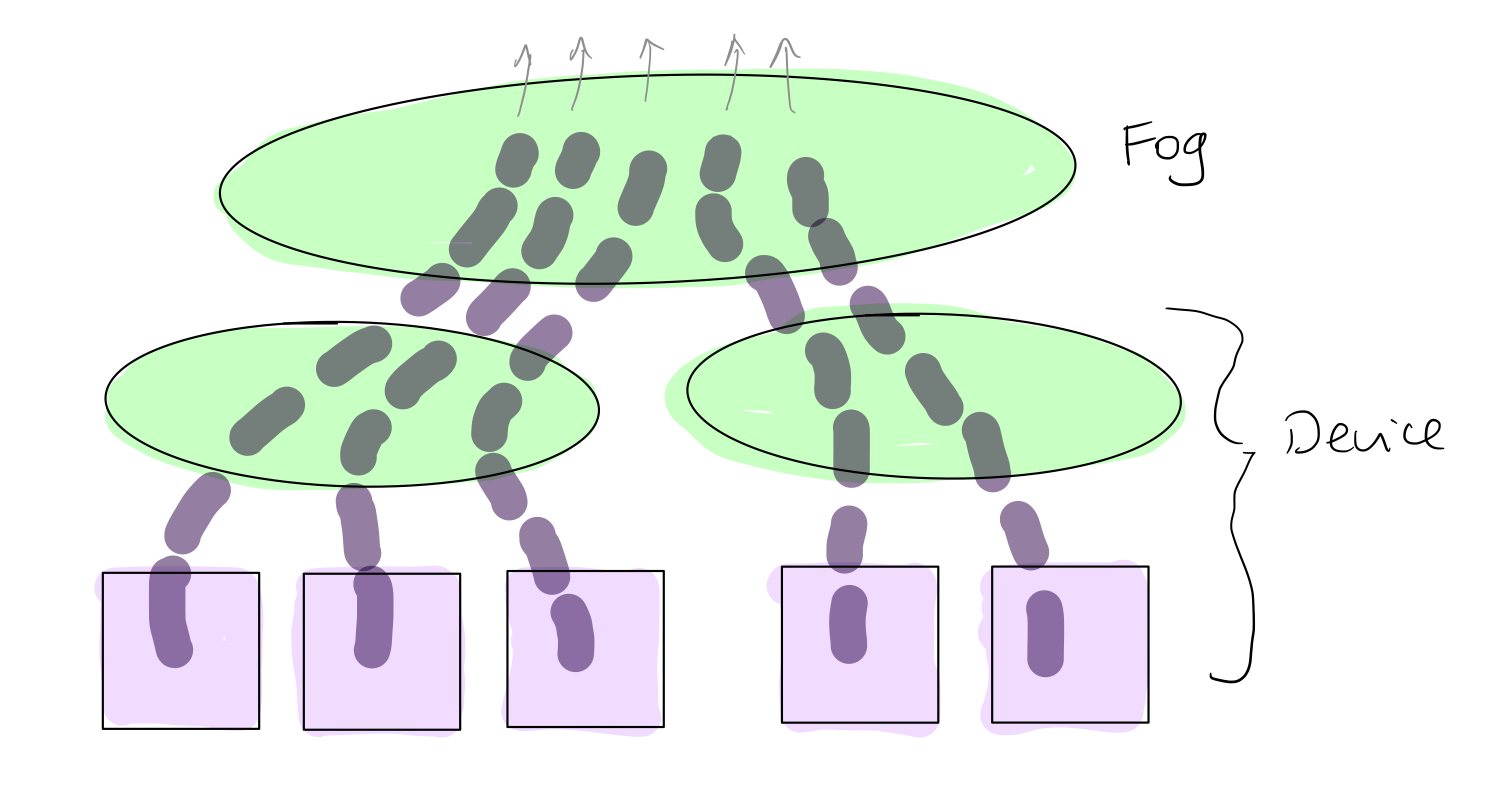
The diagram below shows a scenario where data logging happens from the device to fogs. Still the bulk of the data is produced by workers attached to the devices. The data is funneled through the controllers at the device towards the controller at the fog level. The device-level controller could transform the data or add its own data stream as the data propagates upwards.
Logging Data
The logger that streams the data from the worker towards the controllers at the different levels
is defined using a special jdata section in the J side of a JAMScript program as follows.
jdata {
char *q as logger;
int y as logger;
struct location {
float long;
float lat;
} loc as logger;
}
In the above definition, q is a string logger (i.e., stream of strings with
variable length), y is a stream of integers, and loc is stream of
structures, where each structure contains two floats. The logger is an append
only stream for the worker. That is the worker cannot read the logger. The
controllers can read the logger and obtain values at different positions of the
stream. For instance, the controller can get values by arrival time or by
position (last, first, etc) in the stream.
The following listings show two code segments: the J and C sides, respectively, of a JAMScript program
that is pushing data towards the controller for persistence. The controllers can apply different
types of computations (not shown) on the data. In the J side, the variable name is defined as a
string logger. Also, the J side (controller) is writing a data stream into the logger in addition to reading the
streams that are already part of the logger. The J side is writing different data values depending on its level:
cloud, fog, or device.
jdata {
char *name as logger;
}
var nlogger = name.getMyDataStream();
var count = 1;
setInterval(function() {
if (jsys.type === "cloud")
nlogger.log("fred@cloud-" + count);
else if (jsys.type === "fog")
nlogger.log("fred@fog-" + count);
else
nlogger.log("fred@device-" + count);
for (i = 0; i < name.size(); i++) {
if (name[i] !== undefined)
console.log("I: ", i, " Name ", name[i].lastValue());
else
console.log("Logger value undefined...");
}
count = count + 1;
}, 1000);
The listing below shows the C side of the program that writes to the logger. To write to the logger, we
simply assign a value to the logger. In this case, name is assigned buf that holds the string to be
logged. If jsleep() is used to intersperse the logs, we need to put the logging actions into a local
task so that jsleep() can be used.
jasync logdata() {
char *names[10] = {"david", "mayer", "justin", "richard", "lekan", "ben", "owen", "nicholas", "karu", "clark"};
int i;
char buf[32];
for (i = 0; i < 1000; i++) {
sprintf(buf, "%d-%s", i, names[i % 10]);
name = buf;
printf("Wrote .. name: %s\n", buf);
jsleep(1000);
}
}
int main()
{
logdata();
}
Data Access Scoping in Loggers
When declaring loggers, we can specify the level to store the data: device, fog or cloud. Data can be written from any level at or below the one specified and can only be read to from the level specified. This means that a cloud logger can be written from the device, fog or cloud levels but can only be read from the cloud.
| Specifier | Write Access | Read Access |
|---|---|---|
| Device | Device | Device |
| Fog | Device, Fog | Fog |
| Cloud | Device, Fog, Cloud | Cloud |
Broadcasting Data
While loggers push data from the workers towards controllers, broadcasters do the reverse. They are useful
for the controllers to push control data to the workers or sub controllers.
In the program shown below, two broadcasters x and y are defined. They are string broadcasters.
The J side is pushing different string values on x and y every 100 ms.
jdata {
char *x as broadcaster;
char *y as broadcaster;
}
var count = 1;
setInterval(function() {
var msg = "msg-on-x=" + 2 * count;
x.broadcast(msg);
var msg2 = "msg-on-y=" + (2 * count + 1);
y.broadcast(msg2);
count++;
}, 100);
In the C side, we define a local task to read the incoming value. The local task waits for the value to arrive. Because the braodcaster reception is in a local task, the main thread is still available to process other tasks.
jasync checkx()
{
char *msg;
while(1)
{
msg = x;
printf("%s\n", msg);
}
}
jasync checky()
{
char *msg;
while(1)
{
msg = y;
printf("%s\n", msg);
}
}
int main(int argc, char *argv[])
{
checkx();
checky();
}
We can have programs that combine braadcasting and logging because local tasks can concurrently handle both tasks. However, any other statements in the local tasks such as reading the terminal must be non-blocking.
The broadcaster is written to by the controllers and read by the worker (i.e., the worker cannot write to the broadcaster).