The Controller-Worker Model
JAMScript is based on a controller-worker model. The controllers can be at different levels: cloud, fog, and device levels. The workers can only be in the device level. A controller at the device level can have one or more workers underneath it. Similarly, a controller at the cloud or fog levels can have more or sub controllers in the lower levels underneath it. Those sub controllers can have workers provided the sub controller is in the device level. A worker has exactly one parent controller that is located in the device level. In addition, the worker would be optionally connected to a controller at the fog level and cloud level depending on the system configuration. The controller-worker relationship is symmetric in that a worker that is underneath a controller also sees that controller as its parent.
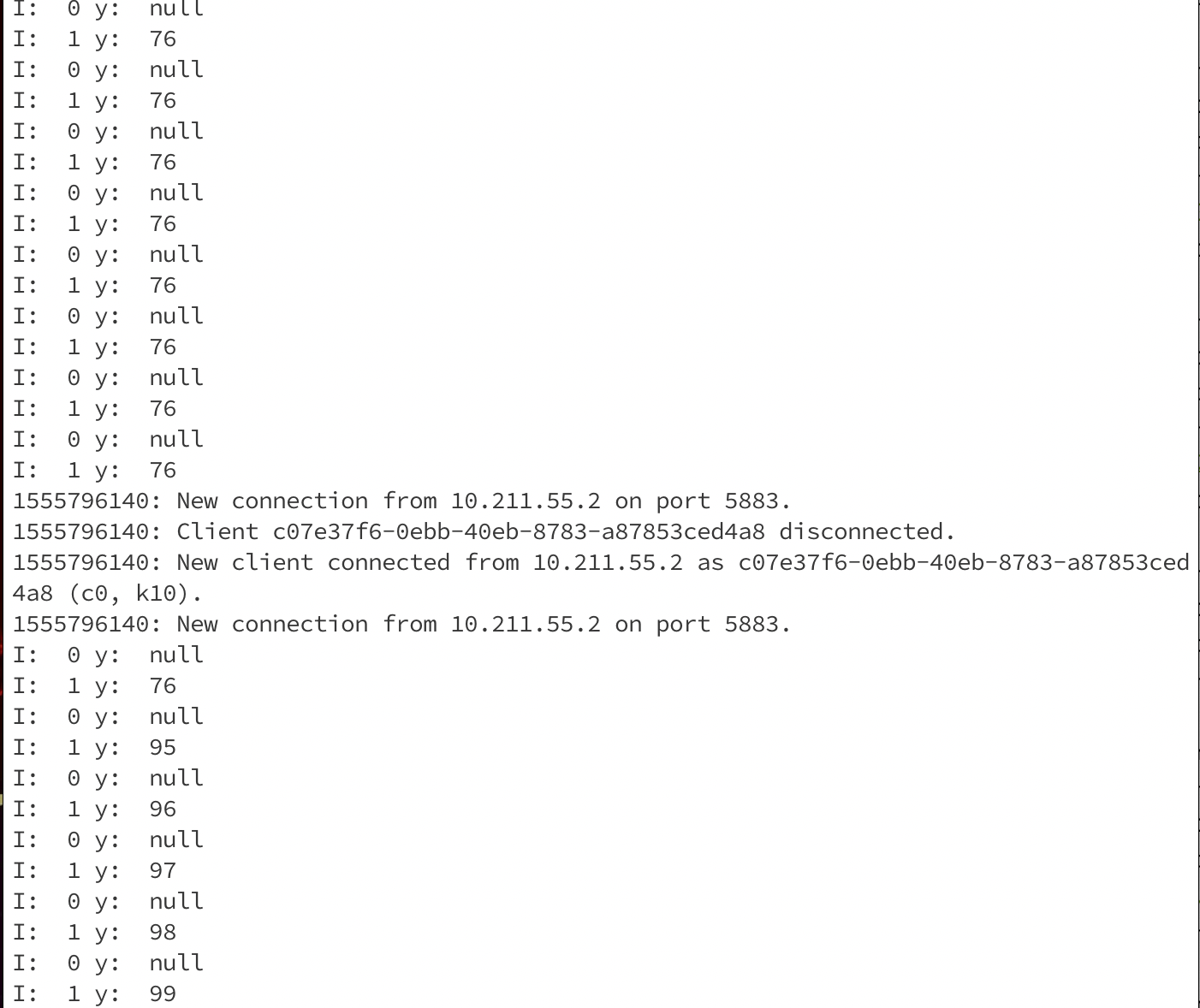
The figure below shows how a controller and three workers would be organized in a single device. In this example, all workers are under the controller in the device. The device is self-contained – that is, the JAMScript program loaded into the device can run even if the device is offline.
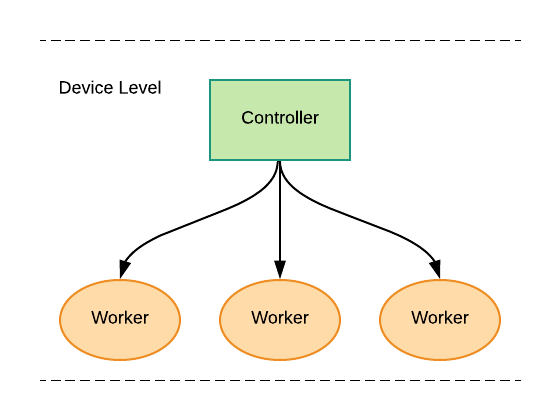
The following figure shows a larger configuration with controllers at the cloud, fog, and device levels. The workers are at the device level. A JAMScript program creates a hierarchical configuration when it is run across multiple devices as shown here.
The JAMScript runtime is responsible for creating the hierarchical configuration among the controllers and workers and different levels. Therefore, JAMScript is highly suitable for creating and maintaining computing structures across collection of nodes that are constantly changing in proximity to one another – for example, vehicular networks.
In JAMScript, the controller is implemented in JavaScript with few JAMScript specific extensions. The worker is implemented in C with few JAMScript specific extensions. The JAMScript specific extensions allow the JAMScript compiler to related both sides and make the necessary connections between the controller and worker so that both sides would work as a whole.
Anatomy of a JAMScript Program
A JAMScript program needs to have a C file and a JavaScript file. The JavaScript (J) file of a toy JAMScript program is shown below. The J side of the program is calling a function testme() every 300 milliseconds. You will notice that testme() is not defined in the J side. So, it must be defined in the C side of the JAMScript program as a remote function (that is, as a function that can be called from the J side).

The C file of the toy JAMScript program is shown below. The testme() function is defined in the file along with two other functions. The testme() function is prepended with the jasync keyword, which indicates that the function is an asynchronous JAMScript task. An asynchronous JAMScript task can be invoked from either side: J side or C side. In this case, the testme() is called from the J side.
The localme() and localyou() are also asynchronous JAMScript tasks, but they are not called from the J side. Instead they are called from the C side itself. Once a JAMScript task is defined it could be called from the local worker or the controller.
Asynchronous JAMScript tasks are run using user-level threads. So, they cannot include any blocking calls like sleep(). You will notice that jsleep() is used to delay the execution of the JAMScript task by the given amount of time.

The main() function launches both JAMScript (local) tasks. The local tasks run concurrently. Because we are using user-level threading in JAMScript, the jsleep() is essential for yielding the execution context to the other concurrently running threads.
Auto Discovery in JAMScript Programs
One of the interesting aspects of JAMScript is the auto discovery of JAMScript program components. A JAMScript executable can be run in different ways: (a) only in a single device, (b) in a single fog and many devices, and (c) cloud, fog, and devices. There is no special configuration file to indicate which configuration is used at any invocation.
Suppose we start a JAMScript program in a device and then in another device. The JAMScript programs in the two devices would run independent of each other – that is, without connecting with one another. Now, if we start a fog instance, all three instances would get connected – automatically! To enable the auto discovery feature, all the JAMScript program instances must be using the same name.
Consider an example JAMScript program where the worker is creating some data and pushing it towards the controllers. A worker could have one to three parent controllers depending on the configuration we use. That is, a worker could have a device level, device and fog level, or device, fog, and cloud level controllers.
The program shown below is the C side of the JAMScript application for logging data. It selects a data string from the 10 available names and logs it to the controller. To log it essentially assigns the local variable (in this case it is buf) to name. You can note that name is not defined in the C side. The main() function of the program just starts the logdata() local task, which is responsible for pushing one data item every 1000 milliseconds.

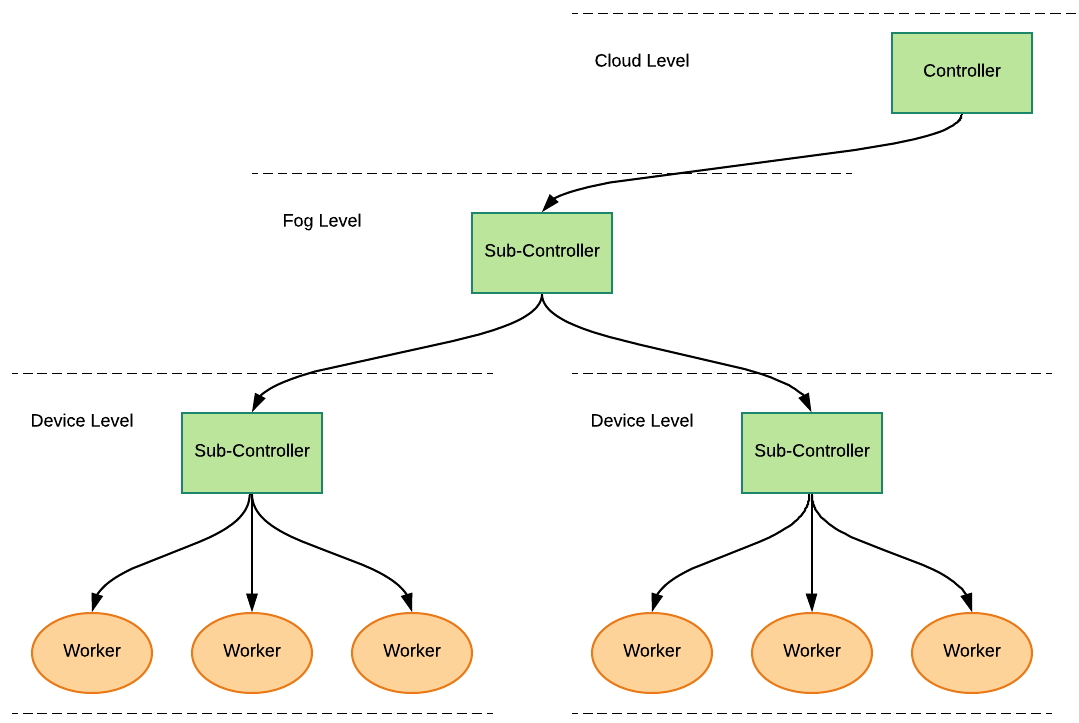
The J side of the JAMScript application is shown below. The first thing you will note is the jdata section. It defines name as a string logger. The logger is a stream of time series data. That is, as the worker logs data we will create a new data item in the stream. The number of streams would correspond to the number of workers (each worker has its own stream). The controllers can also write to the logger.
The J program is doing two things: it is writing to the logger and printing the stream contents. To write to the logger, the controller needs to get access to its own stream and then push the data item to that stream.
The figure below shows one fog and two devices running the above program. The fog-1 is started with the following command line.
jamrun stringlog.jxe --app=test1 --fog --data=127.0.0.1:8000
The stringlog.jxe is the JAMScript executable that is obtained by compiling the source file using jamc.
The program is run under the test1 name. The JAMScript runtime connects all the program components
with the same name and executable filename (there is no authorization checking
step while connecting the program components). The --data option specifies the data store URL. Because
all three components (fog and the two devices) are run in the same machine, we need to
specify URLs with different port numbers.
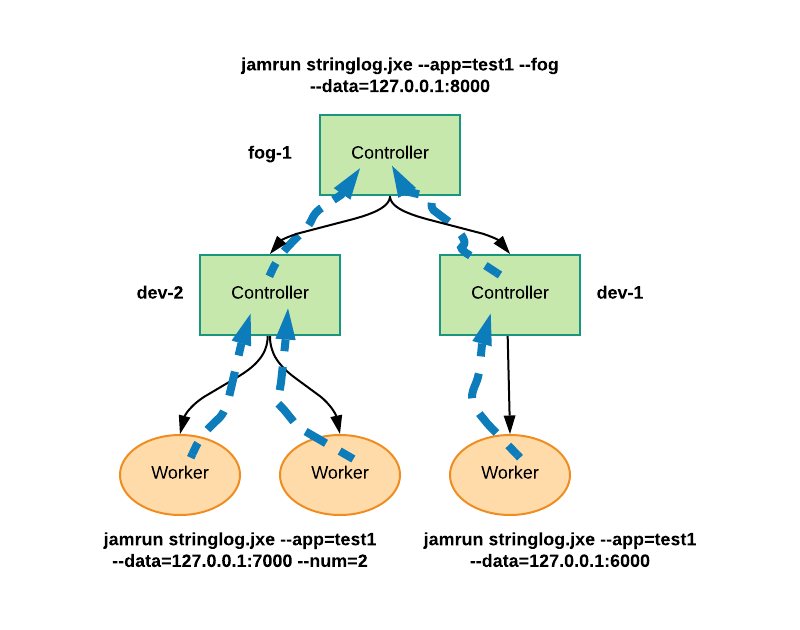
The JAMScript program components can be started in any order. Once they are all started, the configuration as shown above should be formed. We should be able to kill a component and restart it. The configuration will reform after the program components are started and they have discovered each other.
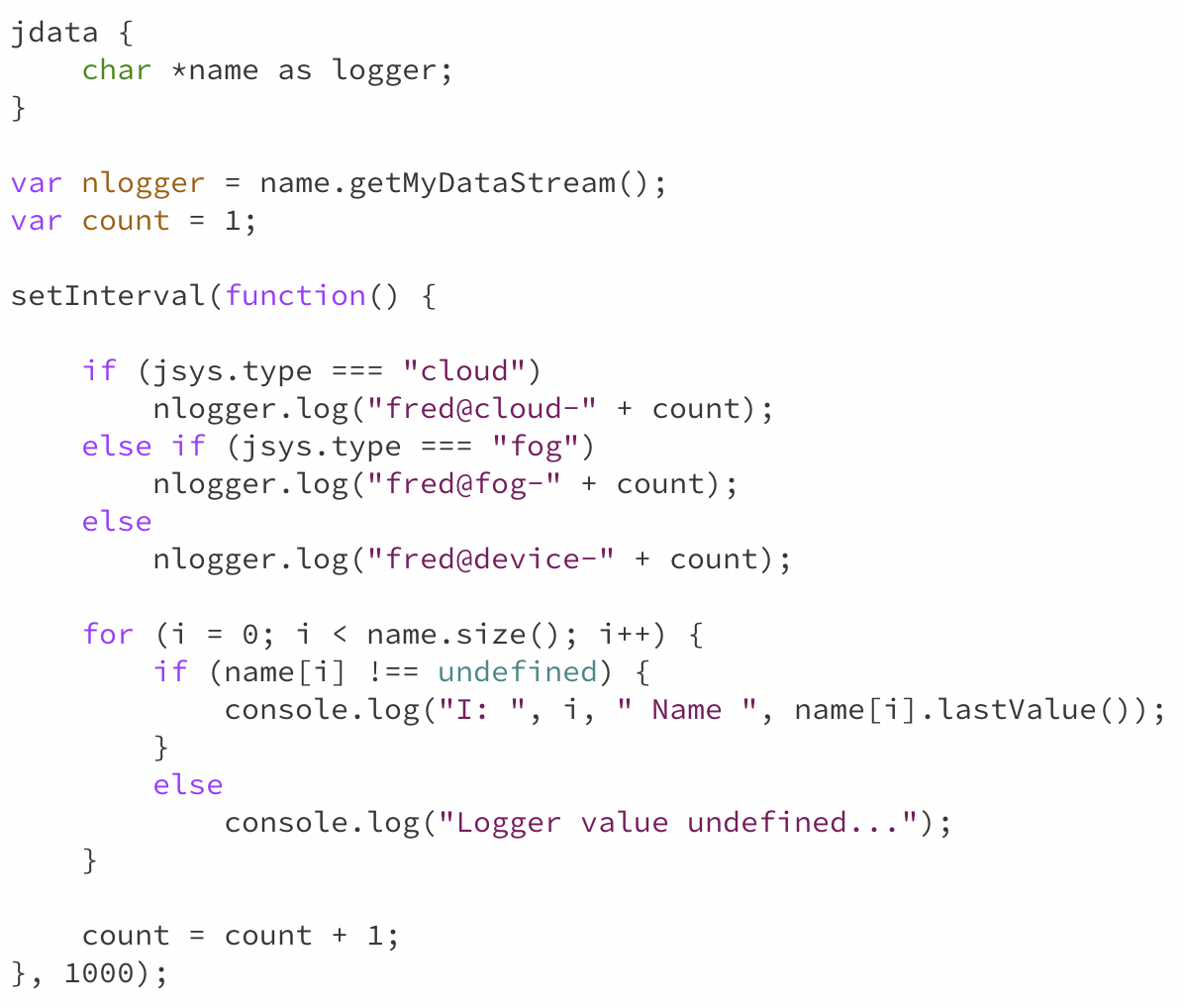
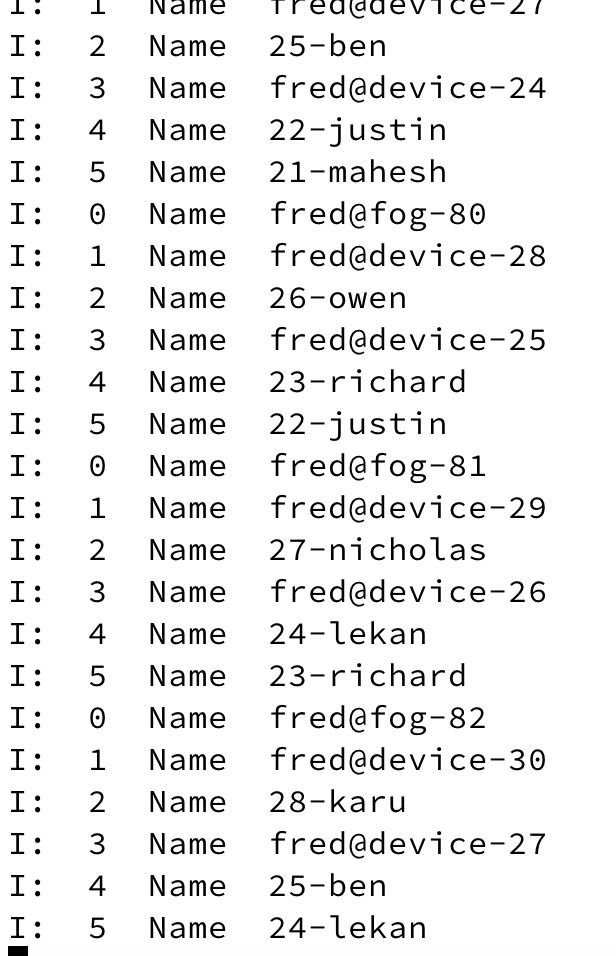
The listing below shows the output at fog-1. You can note that it shows the
streams from both controllers and workers. There are three workers in total and the
output from the worker look like XX-name while the output from the controller looks
like fred@X-Y.
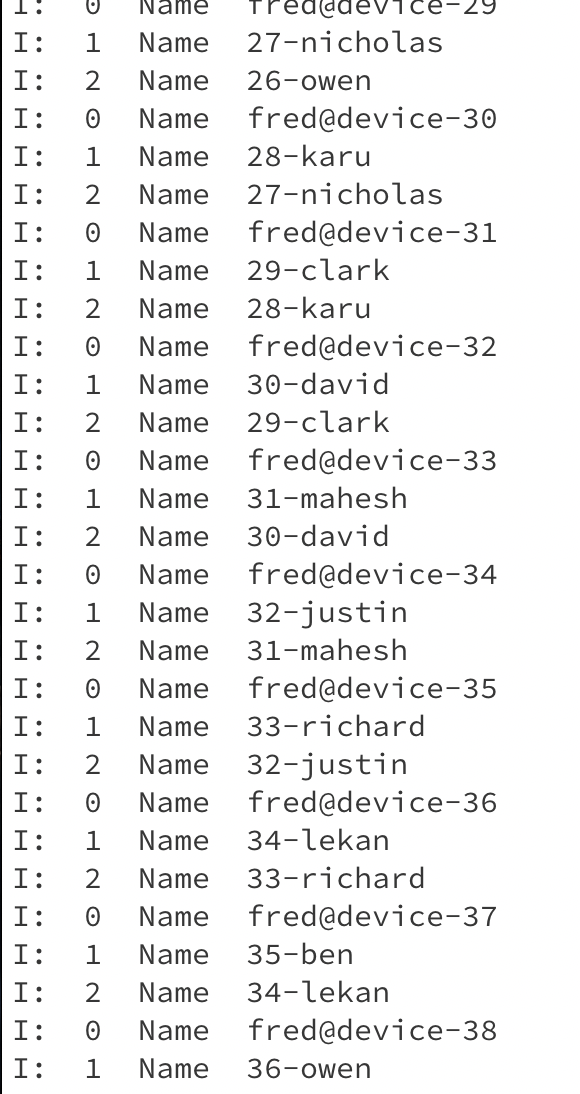
The listing below shows the output at dev-2. You can note that it shows the streams from the two workers and the values from the controller.
Fog Computing + Mobile IoT in JAMScript
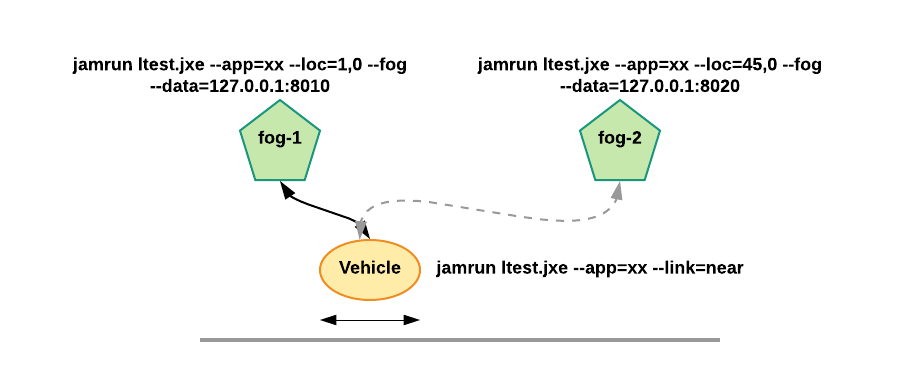
JAMScript has special support for interfacing fog computing with mobile IoT. Using a simple example scenario we illustrate some ways JAMScript can help the use of fog computing in mobile IoT. Let us consider a scenario where two fogs are located in a straight line (e.g., road segment). A vehicle is going back and forth on the road segment and we want it to be associated with the closest fog at any given time. The tasks launched by the vehicle must get executed at the closest fog. Also, when the fogs execute remote tasks the vehicles in their zones would execute those calls and not the vehicles in other fog zones. The same goes to data streams created by the loggers.
The C side of the JAMScript program is shown below. It is a very simple program with a local task that is logging a value every 90 milliseconds.

The J side of the JAMScript program shown below defines what the controller would do. In this application, the controller performs different actions at the fog and device levels. At the fog level, the controller would print stream that is logged by the devices while at the device level it would setup the movement of the device.

The overall setup is shown in the figure below. The fogs are started using the commands given in the figure and the device is started as shown. The command line for starting the fog specifies the geographical location of the fogs. The command line for starting the device specifies that nearest fog should be used by the device. This means as the device moves the fog association would change.
The output of one of the fog servers is shown in the figure below. As we can see the output from the device is reaching one fog and it switches over to another fog.